

Comdigio 3Dシール ぷにぷに 立体デコシール 柔らかい弾力触感 スマホケース・水筒・手帳デコ用 はがしやすい おしゃれ 可愛い 女の子 ごほうび 贈り物 DIY
商品ページAmazon
収益広告(自動登録)
サクラ度:△(要確認)



Shnmersy 柴犬 | テディ お腹 シール 3D【2026新型】柔らかいお腹 ぷにぷにシール かわいい 3D もっちりスクイーズ 解消おもちゃ 衝突防止 ステッカー 手帳用 デコレーション 携帯電話飾り用 日記帳用 車用 手芸用品 [並行輸入品
商品ページAmazon
収益広告(自動登録)
サクラ度:△(要確認)

『ToHeart』プレミアムエディション -Steam 【特典】TVアニメ『ToHeart』Blu-ray Disc(全13話・2枚組)同梱
商品ページAmazon
収益広告(手動登録)
サクラ度:○(問題なし)
記事の概要
Pythonを使ってFeedlyでサイトの更新情報を取得してみた
作成日:2021-10-31
最終更新日:2021-10-31
記事の文字数:3485
情報技術情報技術-WebAPIWebサイト作成
Pythonを使ってFeedlyでサイトの更新情報を取得してみた
Feedlyが公開しているWeb APIを使用して、Pythonで自動的にサイトの更新情報を取得できるようにした。
ので実際のPythonコードを交えてそのやり方のメモをここに残します。
ちなみにコードを書くのは上手くないのでクオリティには目をつぶってください。
以下に記事があったのでこちらの手順に従えばできるかと思います。
アカウント登録手順
以下の画像の場所から登録できます。
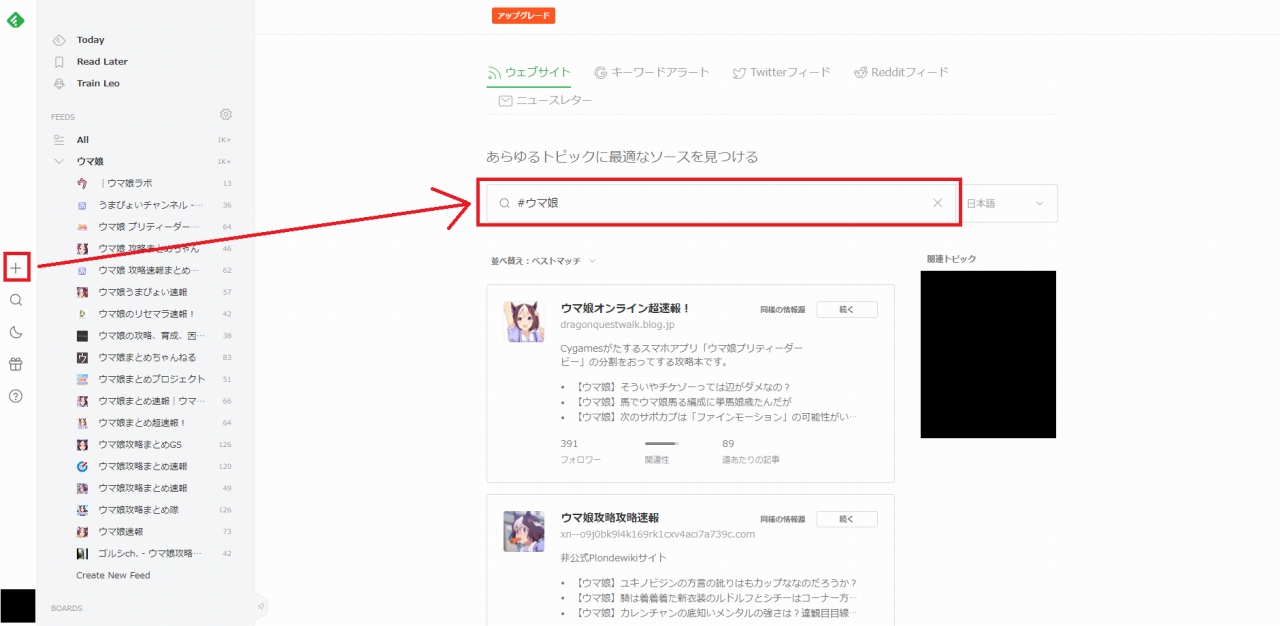 ウマ娘関連のサイトがいっぱい並んでます。
ウマ娘関連のサイトがいっぱい並んでます。
以下のURLから発行できるはずです。
アクセストークン発行ページ OAuthという認証方法を利用しているようですが、無料版ではアクセストークンを画面上でしか取得できないようで、更新(再発行)も画面上のみなので、 アクセストークンが切れる前に画面上で再度アクセストークンを発行し直す必要があります。
アクセストークンの有効期限は30日のようです。
有料版ではリフレッシュトークンを使用して、アクセストークンを再取得できるようです。
WebAPIを叩くためにあらかじめ「requests」パッケージをインポートしておく必要があります。
コードについて重要なところをかいつまんで解説します。
「streamId」というウォッチしたいサイトごとのIDのようなものをパラメータに付与する必要があります。詳細は後述します。
countを指定することで一つのサイトごとに何個の記事を取得するかを指定できます。
独自関数を使用していますが、単にテキストファイルの中に直接書いておいたアクセストークンを取得しているだけです。
アクセストークンの前に「Bearer 」をつけるのを忘れないようにしましょう。
「Authorization」にアクセストークンを付けます。
アクセストークンの前に「Bearer 」をつけるのを忘れないようにしましょう(再掲)。
正常に取得できるとjson形式でレスポンスが来るので、json()メソッドを使って辞書型(MAP型)で受け取ると楽です。
正常に取得できなかった場合にはjson形式でないはずなので、気になる人は例外処理しましょう。
items内の「title」を例文では取得していますが、これはそのページのタイトルです。
実際にどんな情報がjson内に含まれているかは公式のWebAPIのリファレンスを見てください。
当該APIのリファレンス
「CommonFunction.updFileContent」メソッドは単にテキストファイルに保存しているだけです。
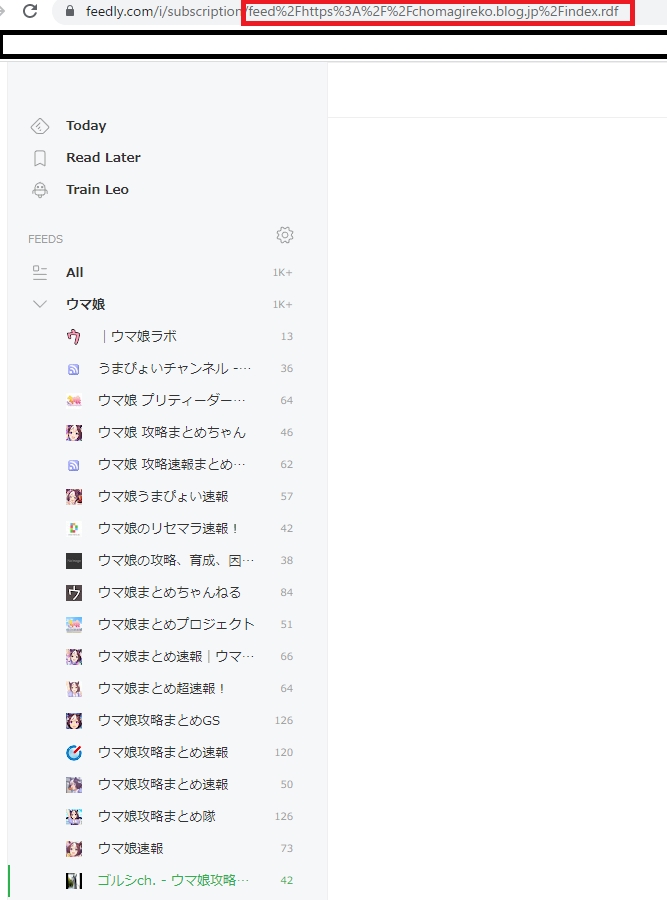
streamIdですが、Feedly のページでそのサイトのページを開いてURLから確認できます。
(もしかしたら知らないだけでもっといい方法があるのかもしれませんが)
ので実際のPythonコードを交えてそのやり方のメモをここに残します。
ちなみにコードを書くのは上手くないのでクオリティには目をつぶってください。
前提
- Feedlyは無料サービスを使用する(有料でどう変わるかがわからなかったため)
- アクセストークン(30日間有効)は手動更新とする(無料では自動更新ができないため)
ざっくりとした流れ
大体の作業の流れは以下の通りです。
このうちpythonで自動化するのは「4~5」デス。
- Feedlyにサービス登録する
- Feedlyに更新をウォッチしたいサイトを登録する
- Feedlyでアクセストークンを発行する
- 【python】サイトの更新情報を取得する
- 【python】取得した情報をテキストファイルに保存する
実作業
1.Feedlyにサービス登録する
まず最初に、当然ですがFeedlyでアカウントを登録する必要があります。以下に記事があったのでこちらの手順に従えばできるかと思います。
アカウント登録手順
2.Feedlyに更新をウォッチしたいサイトを登録する
Feedlyでアカウントを登録したら、最初に更新をウォッチしたいサイトを登録する必要があります。以下の画像の場所から登録できます。
画像クリックで等倍
3.Feedlyでアクセストークンを発行する
APIを利用する上でアクセストークン(APIを利用するために必要なログイン情報)が必要です。以下のURLから発行できるはずです。
アクセストークン発行ページ OAuthという認証方法を利用しているようですが、無料版ではアクセストークンを画面上でしか取得できないようで、更新(再発行)も画面上のみなので、 アクセストークンが切れる前に画面上で再度アクセストークンを発行し直す必要があります。
アクセストークンの有効期限は30日のようです。
有料版ではリフレッシュトークンを使用して、アクセストークンを再取得できるようです。
4.【python】サイトの更新情報を取得する
ここからpythonコードになります。どうでもいいところは中略です。
# パッケージの読み込み
import requests
~~~中略~~~
#-------------------------------------------------------------------
# 記事取得
def getArticle(streamId):
ret = ""
try:
# コールアウトに必要な情報を格納
url = "https://cloud.feedly.com/v3/streams/contents?streamId=" + streamId + "&count=" + artNum
access_token = "Bearer " + CommonFunction.getFileContent(trgtFolder + "AccessToken.txt")
reqHeader = {
"Content-Type":"application/json",
"Authorization":access_token
}
res = requests.get(url, headers=reqHeader)
js = res.json()
for article in js["items"]:
# ここで見たい情報をまとめる
ret += article["title"]
except:
CommonFunction.updFileContent(trgtFolder + "エラー.txt", "ステータスコード:" + str(res.status_code))
return ret
#-------------------------------------------------------------------
記事本体を取得するためのメソッド「getArticle(streamId)」です。WebAPIを叩くためにあらかじめ「requests」パッケージをインポートしておく必要があります。
コードについて重要なところをかいつまんで解説します。
url = "https://cloud.feedly.com/v3/streams/contents?streamId=" + streamId + "&count=" + artNum
WebAPIのエンドポイントURLです。「streamId」というウォッチしたいサイトごとのIDのようなものをパラメータに付与する必要があります。詳細は後述します。
countを指定することで一つのサイトごとに何個の記事を取得するかを指定できます。
access_token = "Bearer " + CommonFunction.getFileContent(trgtFolder + "AccessToken.txt")
ひとつ前の手順で作成したアクセストークンをここで定義します。独自関数を使用していますが、単にテキストファイルの中に直接書いておいたアクセストークンを取得しているだけです。
アクセストークンの前に「Bearer 」をつけるのを忘れないようにしましょう。
reqHeader = {
"Content-Type":"application/json",
"Authorization":access_token
}
WebAPIを叩くときのHTTPリクエストヘッダーです。「Authorization」にアクセストークンを付けます。
アクセストークンの前に「Bearer 」をつけるのを忘れないようにしましょう(再掲)。
res = requests.get(url, headers=reqHeader)
js = res.json()
リクエストに必要なのはエンドポイントURLとリクエストヘッダーだけです。正常に取得できるとjson形式でレスポンスが来るので、json()メソッドを使って辞書型(MAP型)で受け取ると楽です。
正常に取得できなかった場合にはjson形式でないはずなので、気になる人は例外処理しましょう。
res = requests.get(url, headers=reqHeader)
js = res.json()
for article in js["items"]:
# ここで見たい情報をまとめる
ret += article["title"]
取得したサイトの更新情報の1つ1つのページはjsonの「items」内にあるので、ここをループしています。items内の「title」を例文では取得していますが、これはそのページのタイトルです。
実際にどんな情報がjson内に含まれているかは公式のWebAPIのリファレンスを見てください。
当該APIのリファレンス
5.【python】取得した情報をテキストファイルに保存する
以下のように取得した記事の更新情報をテキストファイルに保存しています。「CommonFunction.updFileContent」メソッドは単にテキストファイルに保存しているだけです。
# ウマ娘記事取得
content = ""
content += getArticle("feed%2Fhttps%3A%2F%2Fchomagireko.blog.jp%2Findex.rdf")
CommonFunction.updFileContent(trgtFolder + "ウマ娘.txt", content)
ここで先ほど説明を省略して、「getArticle」メソッドの引数にすべきstreamIdを使っています。streamIdですが、Feedly のページでそのサイトのページを開いてURLから確認できます。
画像クリックで等倍
FeedlyAPIのキツいところ
作った上でFeedlyAPIのキツかったところは以下です。。(もしかしたら知らないだけでもっといい方法があるのかもしれませんが)
- APIの利用回数制限が中々厳しい(24時間で250回? 有料プランだと増えるのかは不明)
- 1回のAPIで1つのサイトの更新情報しか取れない(前述の利用回数制限に抵触しやすくなる)
コメントログ
コメント投稿
管理人ツイート




