





記事の概要
Pythonを使ってinoreaderでサイトの更新情報を取得してみた
作成日:2021-10-31
最終更新日:2021-10-31
記事の文字数:4415
情報技術情報技術-WebAPIWebサイト作成
Pythonを使ってinoreaderでサイトの更新情報を取得してみた
inoreader(イノリーダー?)が公開しているWeb APIを使用して、Pythonで自動的にサイトの更新情報を取得できるようにした。
ので実際のPythonコードを交えてそのやり方のメモをここに残します。
ちなみにコードを書くのは上手くないのでクオリティには目をつぶってください。
以下のURLからアカウントを作成しましょう。
アカウント作成ページ
以下の画像の場所から登録できます。
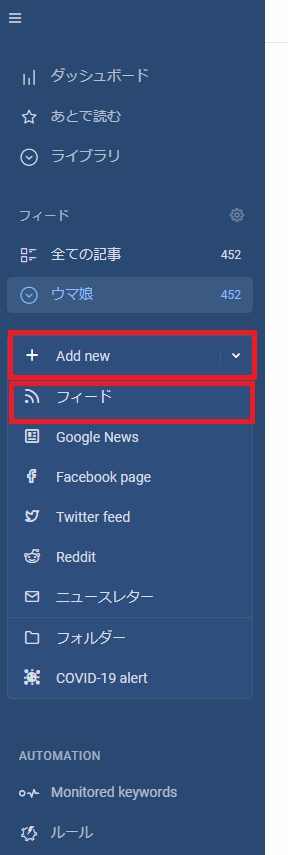 そしてここで更に登録したサイトをフォルダにまとめておきましょう。
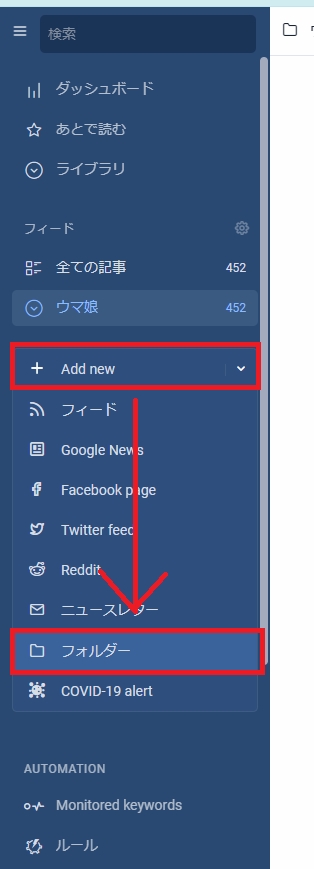
そしてここで更に登録したサイトをフォルダにまとめておきましょう。
後でpythonで更新情報を取得するときに、フォルダ単位で取得できます。
フォルダの作成方法はフィードと同じです。
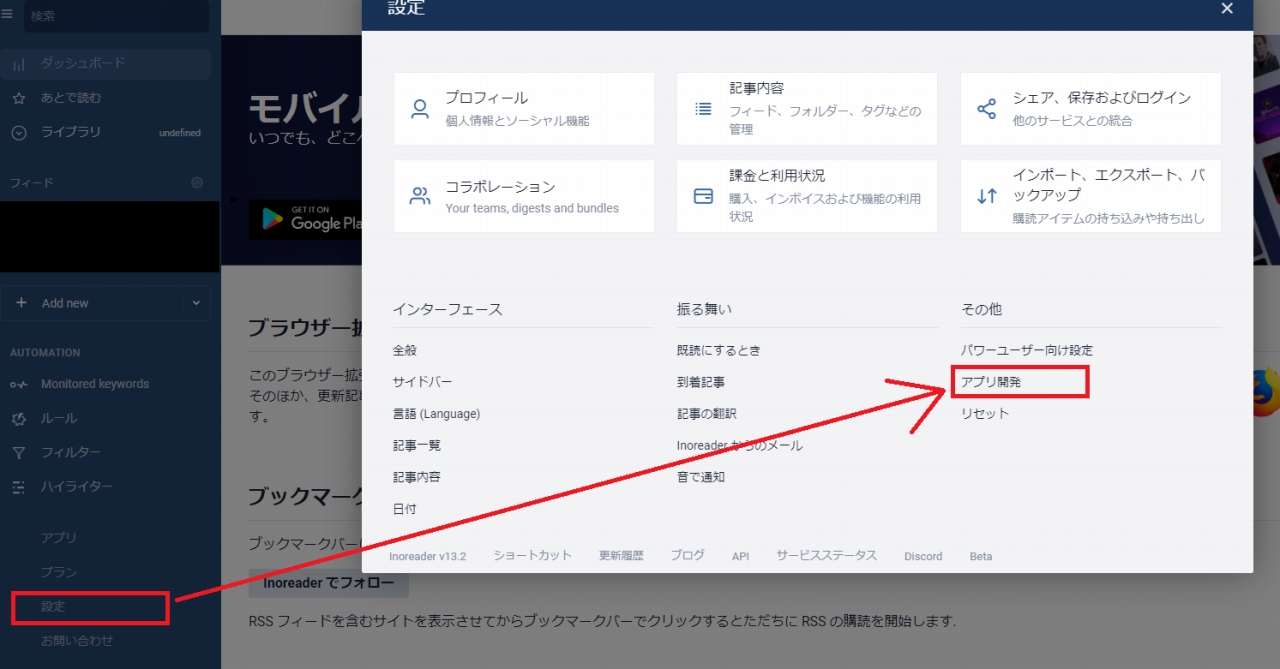
その前段としてinoreader上であらかじめ接続用アプリケーションを作成しておく必要があります。
やり方は以下画像を参考にしてください。
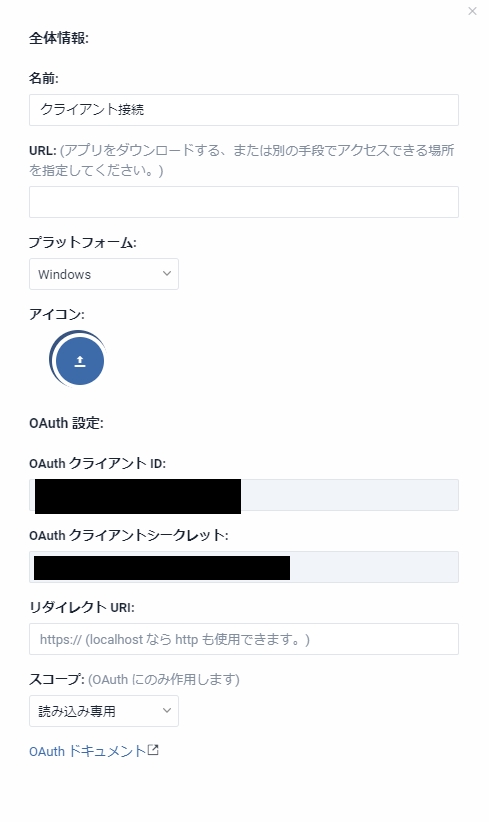
「クライアントシークレット」(App Key)は所謂パスワードのようなもので秘匿性が高いので他の人に教えないようにしましょう。
ただ、のちの工程で必要なので、「クライアントID」と「クライアントシークレット」はメモっておいてください。
ここで間違えそうなところは、リダイレクトURIは特に入れなくてもいいというところです。
まず最初にアクセストークンとリフレッシュトークンを発行しないといけないのですが、ここをpythonで作るとめんどくさいはずで、なおかつ一回しかやらない手順なので、公式がデモのやり方を紹介しているそれに相乗りしました。
以下URLの手順に従い、トークンを発行してください。
「Google OAuth 2.0 Playground」というセクションのところに手順が書いてあります。
アクセストークン発行手順
最後までやるとアクセストークンとリフレッシュトークンが画面に表示されるので、それをメモっておいてください。
記事を取得する流れを記載した「getArticle(streamId)」。
記事本体を取得するための「callAPI(streamId)」。
アクセストークンが期限切れになったときにトークンをリフレッシュする「refleshToken()」。
処理の大まかな流れは、
・まず、「getArticle(streamId)」が呼ばれ、
・その中で「callAPI(streamId)」が呼ばれ、
・その結果ステータスコードが「403」となった場合(これがアクセストークンの有効期限切れを表します)、「refleshToken()」が呼ばれ、もう一度「callAPI(streamId)」が呼ばれ、という流れです。
ちなみに前提として、クライアントシークレットとアクセストークンとリフレッシュトークンは別途それぞれ「ClientSecret.txt」「AccessToken.txt」「RefleshToken.txt」というファイルに保存してあります。
クライアントIDだけコードに直書きしてますが、これは書き換えることもないしそんなに秘匿性が高い情報ではないので直接書いてます。
ここのコードについては、ステータスコード403時の特殊な動きを除けば、あと気になるのは「StreamId」かと思います。
これについては次に説明します。
「CommonFunction.updFileContent」メソッドは単にテキストファイルに保存しているだけです。
最初に作成したフォルダがあると思いますが、StreamIdを単純に言うと「user%2F-%2Flabel%2F{フォルダ名}」みたいにすればいいだけのようです。
ので実際のPythonコードを交えてそのやり方のメモをここに残します。
ちなみにコードを書くのは上手くないのでクオリティには目をつぶってください。
前提
- inoreaderは無料サービスを使用する(無料で十分使えそうだったため)
ざっくりとした流れ
大体の作業の流れは以下の通りです。
このうちpythonで自動化するのは「5~6」デス。
- inoreaderにサービス登録する
- inoreaderに更新をウォッチしたいサイトを登録する
- inoreaderで接続用アプリケーションを登録する
- inoreaderでトークンを発行する(GoogleDevelopers使用)
- 【python】サイトの更新情報を取得する
- 【python】取得した情報をテキストファイルに保存する
実作業
1.inoreaderにサービス登録する
まず最初に、当然ですがinoreaderでアカウントを登録する必要があります。以下のURLからアカウントを作成しましょう。
アカウント作成ページ
2.inoreaderに更新をウォッチしたいサイトを登録する
inoreaderでアカウントを登録したら、最初に更新をウォッチしたいサイトを登録する必要があります。以下の画像の場所から登録できます。
画像クリックで等倍
後でpythonで更新情報を取得するときに、フォルダ単位で取得できます。
フォルダの作成方法はフィードと同じです。
画像クリックで等倍
3.inoreaderで接続用アプリケーションを登録する
inoreaderではFeedlyと違って無料版でもきちんとしたOAuthが使えるようです。その前段としてinoreader上であらかじめ接続用アプリケーションを作成しておく必要があります。
やり方は以下画像を参考にしてください。
「クライアントシークレット」(App Key)は所謂パスワードのようなもので秘匿性が高いので他の人に教えないようにしましょう。
ただ、のちの工程で必要なので、「クライアントID」と「クライアントシークレット」はメモっておいてください。
ここで間違えそうなところは、リダイレクトURIは特に入れなくてもいいというところです。
画像クリックで等倍
画像クリックで等倍
4.inoreaderでトークンを発行する(GoogleDevelopers使用)
前述の通りFeedlyと違い、無料版でもアクセストークンの使用方法がきちんとした奴です。まず最初にアクセストークンとリフレッシュトークンを発行しないといけないのですが、ここをpythonで作るとめんどくさいはずで、なおかつ一回しかやらない手順なので、公式がデモのやり方を紹介しているそれに相乗りしました。
以下URLの手順に従い、トークンを発行してください。
「Google OAuth 2.0 Playground」というセクションのところに手順が書いてあります。
アクセストークン発行手順
最後までやるとアクセストークンとリフレッシュトークンが画面に表示されるので、それをメモっておいてください。
5.【python】サイトの更新情報を取得する
ここからpythonコードになります。どうでもいいところは中略です。
# パッケージの読み込み
import requests
~~~中略~~~
#-------------------------------------------------------------------
# コンテンツ取得
def getArticle(streamId):
# 戻り値を指定
ret = ""
try:
# コンテンツ取得API実行
res = callAPI(streamId)
# ステータスコードが403の場合、アクセストークンを更新し、もう一度コンテンツを取得する
if res.status_code == 403:
#アクセストークンを更新
refleshToken()
# コンテンツ取得API実行
res = callAPI(streamId)
# html文を作成
js = res.json()
for article in js["items"]:
# ここで見たい情報をまとめる
ret += article["title"]
except:
CommonFunction.updFileContent(trgtFolder + "エラー.txt", "ステータスコード:" + str(res.status_code))
return ret
# コンテンツ取得API実行
def callAPI(streamId):
# アクセストークンを取得
accessToken = CommonFunction.getFileContent(trgtFolder + "AccessToken.txt")
# API利用に必要な情報を格納
url = "https://www.inoreader.com/reader/api/0/stream/contents/" + streamId + "?n=" + artNum
reqHeader = {
"Content-Type":"application/x-www-form-urlencoded",
"Authorization":"Bearer " + accessToken
}
# コンテンツ取得APIを実行
res = requests.get(url, headers=reqHeader)
return res
# アクセストークンを更新
def refleshToken():
# リフレッシュトークンを取得
refToken = CommonFunction.getFileContent(trgtFolder + "RefleshToken.txt")
# API利用に必要な情報を格納
url = "https://www.inoreader.com/oauth2/token"
reqHeader = {
"Content-Type":"application/x-www-form-urlencoded"
}
reqParam = {
"client_id":"**********",
"client_secret":CommonFunction.getFileContent(trgtFolder + "ClientSecret.txt"),
"grant_type":"refresh_token",
"refresh_token":refToken
}
# トークンリフレッシュAPIを実行
res = requests.post(url, headers=reqHeader, data=reqParam)
CommonFunction.updFileContent(trgtFolder + "RefleshTokenBK.txt", res.json()) # 念のためリフレッシュした時のレスポンスを全部保存
# アクセストークンをファイルに保存
CommonFunction.updFileContent(trgtFolder + "AccessToken.txt", res.json()["access_token"])
# リフレッシュトークンをファイルに保存
CommonFunction.updFileContent(trgtFolder + "RefleshToken.txt", res.json()["refresh_token"])
#-------------------------------------------------------------------
メソッドが3つあります。記事を取得する流れを記載した「getArticle(streamId)」。
記事本体を取得するための「callAPI(streamId)」。
アクセストークンが期限切れになったときにトークンをリフレッシュする「refleshToken()」。
処理の大まかな流れは、
・まず、「getArticle(streamId)」が呼ばれ、
・その中で「callAPI(streamId)」が呼ばれ、
・その結果ステータスコードが「403」となった場合(これがアクセストークンの有効期限切れを表します)、「refleshToken()」が呼ばれ、もう一度「callAPI(streamId)」が呼ばれ、という流れです。
ちなみに前提として、クライアントシークレットとアクセストークンとリフレッシュトークンは別途それぞれ「ClientSecret.txt」「AccessToken.txt」「RefleshToken.txt」というファイルに保存してあります。
クライアントIDだけコードに直書きしてますが、これは書き換えることもないしそんなに秘匿性が高い情報ではないので直接書いてます。
ここのコードについては、ステータスコード403時の特殊な動きを除けば、あと気になるのは「StreamId」かと思います。
これについては次に説明します。
6.【python】取得した情報をテキストファイルに保存する
以下のように取得した記事の更新情報をテキストファイルに保存しています。「CommonFunction.updFileContent」メソッドは単にテキストファイルに保存しているだけです。
content = ""
content += getArticle("user%2F-%2Flabel%2Fウマ娘")
CommonFunction.updFileContent(trgtFolder + "ウマ娘.txt", content)
「user%2F-%2Flabel%2Fウマ娘」が「StreamId」です。最初に作成したフォルダがあると思いますが、StreamIdを単純に言うと「user%2F-%2Flabel%2F{フォルダ名}」みたいにすればいいだけのようです。
inoreaderAPIのいいところ
- API制限数が明白になっていること
- 無償版でも普通に使えるだけのAPI制限数になっていること
inoreaderAPIのキツいところ
作った上でinoreaderAPIのキツかったところは以下です。- FeedlyAPIと違い、記事のサムネイルを取得できない
コメントログ
コメント投稿
管理人ツイート



